👉 Des fiches d'exercices (non visibles actuellement sur l'application) existent, elles sont disponibles depuis le site internet https://www.digischool.fr/lycee
I. Définitions
Lorsqu’on étudie conjointement deux caractères (ou variables) et sur une même population de taille , on associe à chaque individu de la population un couple , où et sont les valeurs respectives des variables et prises par l’individu « numéro » (où est un nombre entier entre et , ou parfois entre et ).
Définition :
On appelle série statistique double l’ensemble des couples associés à chaque individu de la population. On la présente en général dans un tableau.

Remarque : La liste des valeurs associées à la variable est une série statistique simple dont on peut calculer la moyenne . Il en va de même pour les valeurs de , dont la moyenne est :
et
Définition :
On appelle point moyen de la série statistique double le point de coordonnées , où : et
Le point représente le barycentre des points du nuage de points associé à la série.
Définition :
À chaque couple de la série statistique double , on peut associer le point de coordonnées dans un repère.
L’ensemble de ces points est appelé nuage de points associé à la série statistique double .
II. Exemple
On étudie la taille (en cm), notée , et le poids (en kg), noté , de 8 élèves. On recueille les données suivantes :
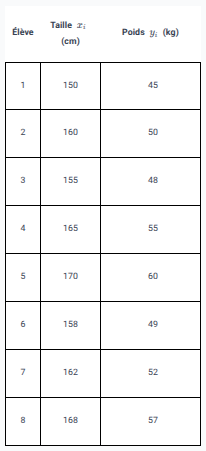
La série statistique double est l’ensemble des couples suivants :
On peut calculer les moyennes des variables et .
Pour la taille :
Pour le poids :
Le point moyen de la série est donc le point de coordonnées .

On cherche s’il existe un lien entre ces deux variables, l’altitude et la température.
On va donc essayer de trouver une courbe qui « approche au mieux » le nuage, c’est-à-dire une courbe qui passe au plus près des points du nuage.
On dit que l’on a effectué un ajustement.
Cette courbe d’ajustement, si elle existe, représente alors une fonction qui permet quasiment d’exprimer la variable en fonction de la variable , sous la forme .
Ici, les points sont presque alignés, donc on peut ajuster le nuage par une droite :
on a donc quasiment une relation du type : entre les deux variables et de la série statistique.

