Introduction
Quand tu ouvres un site Internet, tu vois une page composée de texte, d’images et parfois de vidéos. Pourtant, derrière cette apparence se cache un code que ton navigateur traduit pour toi. Ce code repose sur deux langages complémentaires : HTML, qui décrit le contenu, et CSS, qui en définit l’apparence. Ensemble, ils constituent la base de toutes les pages Web.
Comprendre leur fonctionnement, c’est apprendre à lire la langue du Web et à comprendre comment une page passe du code au visuel que tu vois à l’écran.
Aux origines du Web
L’histoire du Web commence dans les années 1960, lorsque Ted Nelson (chercheur américain, né en 1937) invente le concept d’hypertexte, un texte capable de renvoyer vers un autre grâce à des liens. En 1989, au CERN (Conseil Européen pour la Recherche Nucléaire), Tim Berners-Lee (informaticien britannique, né en 1955) conçoit un système universel de partage d’informations entre chercheurs. Il invente trois outils essentiels :
HTML (HyperText Markup Language, « langage de balisage hypertexte »), pour structurer le contenu.
HTTP (HyperText Transfer Protocol, « protocole de transfert hypertexte »), pour faire circuler les pages sur le réseau.
URL (Uniform Resource Locator, « localisateur uniforme de ressource »), pour identifier chaque page du Web.
En 1993, le premier navigateur graphique, Mosaic, rend le Web accessible à tous. Deux ans plus tard, apparaissent JavaScript (langage de programmation créé par Brendan Eich en 1995) et CSS (Cascading Style Sheets, « feuilles de style en cascade »), qui apportent respectivement l’interactivité et la mise en forme.
Au début des années 2000, le W3C (World Wide Web Consortium, « consortium mondial du Web »), fondé par Tim Berners-Lee, standardise le DOM (Document Object Model, « modèle objet du document ») pour garantir une lecture identique des pages sur tous les navigateurs.
Depuis ces débuts, le Web est devenu un espace ouvert et universel, fondé sur la collaboration et l’accès libre au savoir.
À retenir
Le Web est né du besoin de partager l’information. Grâce à Tim Berners-Lee, Mosaic et la normalisation du W3C, il est devenu un espace mondial, interactif et accessible à tous.
HTML : le langage du contenu
Le langage HTML (HyperText Markup Language, « langage de balisage hypertexte ») sert à structurer le contenu d’une page Web.
Chaque élément est entouré de balises < > qui indiquent sa fonction : p pour un paragraphe, h1 pour un titre, img pour une image.
Une page HTML est organisée en deux parties :
La section head, qui contient les métadonnées (titre, encodage du texte, lien vers le fichier CSS).
La section body, qui contient le contenu visible de la page.
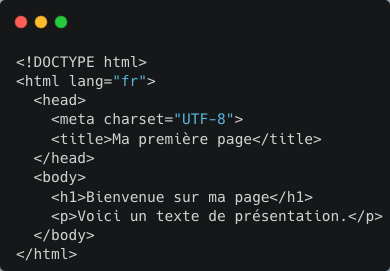
Tu peux créer ta première page Web en ouvrant un simple fichier texte enregistré avec l’extension .html. Tu dois y insérer un titre h1 et un paragraphe p, puis ouvre le fichier dans ton navigateur : le code devient une page visible.
À retenir
Le HTML définit la structure d’une page Web. Il organise le contenu sans préciser sa mise en forme.
CSS : le langage du style
Le CSS (Cascading Style Sheets, « feuilles de style en cascade ») complète le HTML. Il permet de définir l’apparence visuelle : couleur, taille, police ou disposition des éléments.

En SNT, un élève peut modifier le style d’un titre : il ouvre un fichier .css, y écrit h1 {color: red;} et observe comment la couleur de son titre change. Il comprend ainsi que le CSS s’occupe uniquement de la présentation, tandis que le HTML conserve la structure du texte.
Le W3C (World Wide Web Consortium, « consortium mondial du Web ») fixe les normes qui garantissent que les pages s’affichent de la même manière sur tous les navigateurs. Il veille aussi à leur accessibilité, pour que toute personne, y compris en situation de handicap, puisse lire ou écouter le contenu grâce à des outils adaptés.
À retenir
Le CSS définit le style et la mise en page. En séparant la forme (CSS) du fond (HTML), le Web devient plus clair, cohérent et accessible.
URL, HTTP, HTTPS et modèle client/serveur
Chaque page Web possède une adresse unique, appelée URL (Uniform Resource Locator, « localisateur uniforme de ressource »), qui indique au navigateur où trouver la page sur Internet.
Par exemple, dans https://www.education.gouv.fr/secondaire :
httpsdésigne le protocole de communication utilisé.www.education.gouv.frest le nom de domaine du serveur./secondaireindique le chemin vers le fichier demandé.
Le protocole HTTP (HyperText Transfer Protocol, « protocole de transfert hypertexte ») permet d’échanger des données entre un navigateur et un serveur. Sa version sécurisée, HTTPS (HyperText Transfer Protocol Secure, « protocole de transfert hypertexte sécurisé »), chiffre les échanges grâce à un certificat SSL/TLS (Secure Sockets Layer / Transport Layer Security, « couche de connexion sécurisée / sécurité du transport »).
Ce certificat protège les données personnelles des utilisateurs, comme les identifiants ou les paiements en ligne.
Le Web fonctionne selon le modèle client/serveur : ton navigateur (le client) envoie une requête à un serveur distant, qui renvoie la page demandée. Ce dialogue, rapide et invisible, est à la base de chaque clic que tu fais sur Internet.
À retenir
L’URL localise la ressource, le protocole HTTP la transporte, et HTTPS protège l’échange. Le modèle client/serveur fait communiquer ton navigateur et le serveur du site.
Comment le navigateur affiche une page
Quand il reçoit le code d’une page, le navigateur télécharge les fichiers HTML, CSS et les images, puis crée une structure appelée DOM (Document Object Model, « modèle objet du document »). Cette structure en forme d’arborescence organise tous les éléments de la page : titres, paragraphes, liens, images. Ensuite, le navigateur applique les styles CSS à chaque élément et affiche la page complète à l’écran.
Le DOM, normalisé par le W3C (World Wide Web Consortium), garantit que tous les navigateurs interprètent le code de la même manière. Il permet aussi la création de pages dynamiques grâce à des langages comme JavaScript (créé en 1995 par Brendan Eich, informaticien américain), qui peuvent modifier le DOM sans recharger la page. Par exemple, lorsqu’un message apparaît automatiquement ou qu’un menu se déploie, c’est une action JavaScript sur le DOM. En SNT, il ne s’agit pas d’apprendre ce langage, mais de comprendre le principe de cette interactivité.
À retenir
Le navigateur transforme le code HTML et CSS en une page visible grâce au DOM. Ce modèle assure la compatibilité entre navigateurs et rend les pages interactives.
Sites statiques et sites dynamiques
Les premiers sites Web étaient statiques : leur contenu restait identique tant qu’un développeur ne le modifiait pas. Aujourd’hui, la majorité des sites sont dynamiques : ils adaptent leur contenu selon l’utilisateur ou le contexte. Par exemple, un site de météo affiche automatiquement la température de ta ville, tandis qu’un site d’actualités met en avant les articles récents. Ces changements sont gérés par des programmes exécutés sur le serveur.
À retenir
Un site statique affiche toujours la même page, tandis qu’un site dynamique adapte son contenu à la situation ou à l’utilisateur.
Conclusion
Le Web repose sur une architecture simple et universelle : HTML pour structurer le contenu, CSS pour la mise en forme, et les protocoles HTTP/HTTPS pour la communication entre client et serveur. Les navigateurs interprètent ce code via le DOM, garantissant des pages lisibles et interactives.
Mais naviguer sur le Web, c’est aussi exercer une responsabilité numérique : vérifier la fiabilité des sites, protéger ses données personnelles, choisir des mots de passe sûrs et reconnaître les pages sécurisées. Grâce aux normes du W3C et à la vision de Tim Berners-Lee, le Web reste un espace fondé sur la liberté, la coopération et le respect de chacun.